
目录
SATA是硬盘最广泛使用的接口协议。本文简单介绍 SATA 协议栈,希望能让读者理解其中各种机制的目的,并了解部分细节。在你阅读几百页冗长的 SATA Specification 前,可以先阅读本文,获得一个整体把握
本人开源了一个 SATA Gen2 host (HBA) core,可运行在具有 GTH 的 Xilinx FPGA 上。提供基于netfpga-sume?官方开发板的示例,可实现硬盘读写:
github : 开源 SATA HBA,可运行在具有 GTH 的 Xilinx FPGA 上?github.com/WangXuan95/FPGA-SATA-HBA
SATA 接口如图1,其中 SATA host bus adaptor (HBA) 是硬盘读写控制器,在电脑中往往用主板芯片组来实现(在我的开源项目中,HBA是用FPGA来实现的)。而 SATA device 就是硬盘(机械硬盘或固态硬盘)。它们之间用两对差分对连接,其中 (SATA_A+, SATA_A-) 差分对是 HBA 发送、device 接收(也即对 HBA 来说是 TX 通道,对 device 来说是 RX 通道); (SATA_B+, SATA_B-) 差分对是 device 发送、HBA 接收(对 HBA 来说是 RX 通道,对 device 来说是 TX 通道)。两个通道的速率时钟是一样的,分别为:
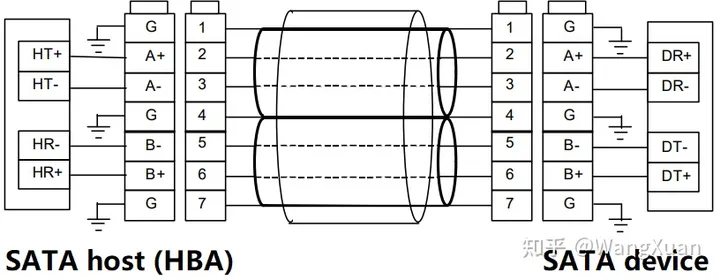
图1:SATA接口(两对差分对)
图2(上)?是一个固态硬盘的SATA接口的照片,其中左边较窄的 7PIN 口是信号接口,两个差分对 (SATA_A, SATA_B) 都包含在里面。右边较宽的 15PIN 口用于给硬盘供电。这些 PIN 的引脚定义如图2(下)。
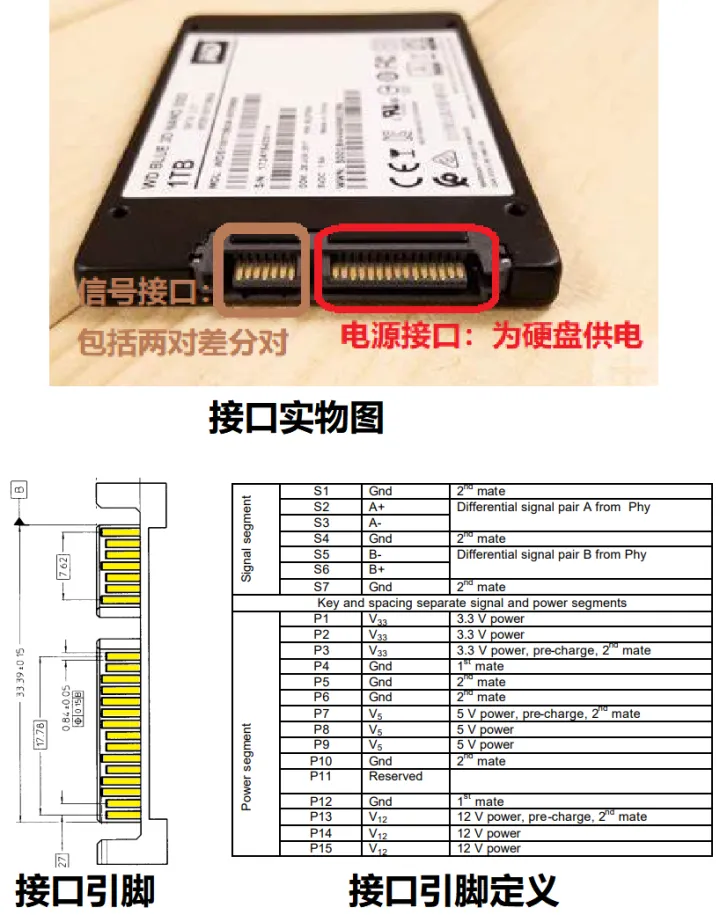
图2:SATA硬盘接口实物图(上);接口引脚定义(下)
图3是SATA的线缆,左边是电源线,能把台式机电源提供的 4PIN 电源口转为 15PIN 的 SATA 电源口。右边是信号线,一端插硬盘上的 7PIN 口,另一端插 HBA 。

图3:SATA电源线缆(左);SATA信号线缆(右)
如图4是 SATA 协议栈结构,从下游到上游包含:物理层(Physical Layer, PHY)、链路层(Link Layer)、传输层(Transport Layer)、命令层(Command Layer) 。

图4:SATA 协议栈
物理层的下游用两对串行差分信号对连接 SATA device ,上游与链路层之间传输并行信号。物理层进行的主要工作包括:
本文将链路层和传输层合起来讲,因为二者间耦合度较大,个人认为合起来更好理解。链路层和传输层需要实现:8b10b 编解码、原语生成和检测(包括FIS包边界识别)、加扰/解扰、CRC生成和检验、流控。最后,传输层与上游的命令层使用一种叫?Frame Information Structures?(FIS) 的数据包结构进行交互。链路、传输层功能分别说明如下:
以上讲了这么多功能可能导致读者搞不清它们的逻辑关系,举例来说,一个链路层和传输层的结构图5。
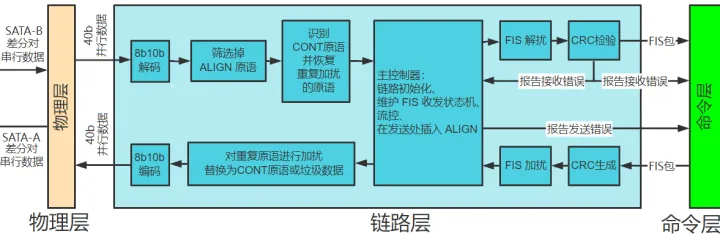
图5:链路层和传输层的实现举例
命令层:接受上游的读写命令,生成和解析命令FIS,实现硬盘读写操作。SATA 支持 ATA 和 ATAPI 命令集,每个命令集包含多种硬盘读写方式,比如 PIO 方式、 DMA 方式等,因此一个完整的命令层需要实现众多繁杂的命令的状态机,但其目的并不复杂,都是为了用各种方式来实现硬盘读写。本文仅会简单地介绍 DMA 方式:包括如何用 DMA 方式发送和接收 FIS ,从而进行硬盘的读写。
目前为止,读者已经对 SATA 协议栈有了粗浅的理解。下文将从链路层往上开始逐个讲解一些细节。本人并不了解物理层的细节,因此本文不讲物理层。
系统上电后,HBA 和 device 之间需要进行链路初始化(link initialize)。在初始化之前,HBA 和 device 之间显然还不能正常地传输 FIS 数据,因此 SATA 使用带外信号 (OOB signal) 来检测对方是否存在,从而进行链路初始化。之所以称为“带外”信号,是因为它是将差分对驱动到相同的公共电压,即不对应逻辑0也不对应逻辑1 。
规定差分线电平不同(逻辑0或逻辑1)为 SIGNAL ,差分线电平相同为 NOSIGNAL 。SATA 规定了两种 OOB 信号:
图6是链路初始化的时序图,首先,HBA 发送一个 COMINIT ,并等待 device 回复 COMINIT。 如果没有收到 COMINIT,主机可以发送更多 COMINIT ,直到收到一个为止。然后主机向设备发送 COMWAKE,并等待 device 回复 COMWAKE 。 此后,HBA 向 device 不断发送一个特殊的数据 DIAL-TONE (翻译为拨号音,是1和0交替的模式) ,并等待 device 发来 ALIGN 原语,device 发送 ALIGN 原语后, HBA 也发送 ALIGN 原语给 device ,即可完成链路初始化。初始化后,HBA 和 device 都向对方发送持续的 SYNC 原语,代表自己处于空闲状态,已经准备好收发 FIS 了。
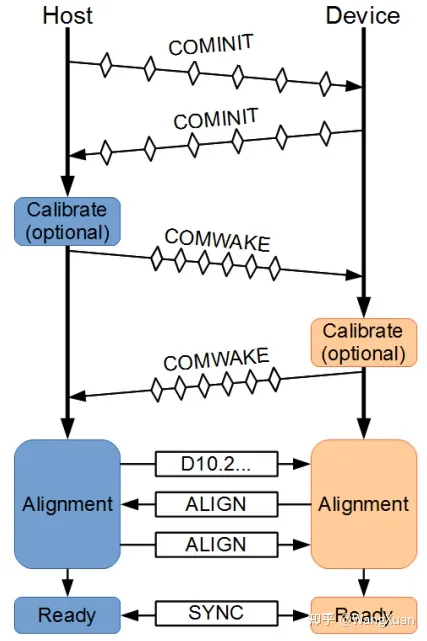
图6:链路初始化的时序图。摘自参考资料[3]
链路初始化后,SATA 始终都在传输原语和数据(可以称为带内信号)。SATA 中所有原语的长度(在8b10b 编码之前)都为 4 byte (1 dword) ,而除了原语外其它时间传输的都是数据(虽然并不一定是 FIS 数据,也可以是FIS外的垃圾数据),数据也都以 1 dword 为单位。
dword 翻译为“双字”,是 4 byte 的意思。
本文涉及的原语和数据如表1(有几个不常用的原语没有列出来),其中 byte 形式和 dword 形式都是在 8b10b 编码之前。
注意 SATA 中所有的 dword 都是小端序,表示为 byte 形式后,低字节在前,高字节在后,在物理层传输时,也是先传输 dword 的低字节,后传输 dword 的高字节。例如对于 ALIGN 原语,字节 BC 会先传送,字节 7B 会最后传送。
表1:SATA 原语定义
| 名称 | byte形式(16进制) | dword形式(16进制) | 首个byte是否为K | 功能/含义 |
|---|---|---|---|---|
| ALIGN | BC 4A 4A 7B | 7B4A4ABC | 是 (K28.5) | 字节对齐 |
| CONT | 7C AA 99 99 | 9999AA7C | 是 (K28.3) | 重复原语加扰/解扰 |
| SYNC | 7C 95 B5 B5 | B5B5957C | 是 (K28.3) | 空闲(不在传输FIS) |
| R_RDY | 7C 95 4A 4A | 4A4A957C | 是 (K28.3) | 准备好接收 FIS |
| R_IP | 7C B5 55 55 | 5555B57C | 是 (K28.3) | 正在接收 FIS |
| R_OK | 7C B5 35 35 | 3535B57C | 是 (K28.3) | 接收 FIS 成功 |
| R_ERR | 7C B5 56 56 | 5656B57C | 是 (K28.3) | 接收 FIS 出错 |
| X_RDY | 7C B5 57 57 | 5757B57C | 是 (K28.3) | 准备好发送 FIS |
| SOF | 7C B5 37 37 | 3737B57C | 是 (K28.3) | 发送 FIS 开头 |
| EOF | 7C B5 D5 D5 | D5D5B57C | 是 (K28.3) | 发送 FIS 结尾 |
| WTRM | 7C B5 58 58 | 5858B57C | 是 (K28.3) | 发送 FIS 结束 |
| HOLD | 7C AA D5 D5 | D5D5AA7C | 是 (K28.3) | 流控 |
| HOLDA | 7C AA 95 95 | 9595AA7C | 是 (K28.3) | 流控 |
| DIAL-TONE | 4A 4A 4A 4A | 4A4A4A4A | 否 | 链路初始化时使用 |
| DATA(普通数据) | XX XX XX XX | XXXXXXXX | 否 | FIS数据或垃圾数据 |
注意表1中的 DATA(普通数据) 的 XXXXXXXX 的含义是普通数据是可以取任意值的 dword 。
阅读表1,你可能会对原语和数据的区分问题发出疑问:比如如果一个普通数据刚好是 0xB5B5957C ,和 SYNC 原语一样,那么该怎么区分出它是数据,而不是 SYNC 原语?实际上这是依赖于额外的信息:要看该 dword 的首个byte (最低byte) 是否被编码为 K 。为 K 则是原语,否则就是普通数据。是否为 K 实际上是 1bit 的额外信息,是用 8b10b 编码来实现的(详见下文:8b10b编码)。
注意到链路初始化所使用的 DIAL-TONE 的首 byte 并不是 K ,这意味着 DIAL-TONE 并不是原语,也不能与普通数据 0x4A4A4A4A 区分开来。实际上,因为 DIAL-TONE 只是链路初始化前的概念,所以在链路初始化前遇到的 的 0x4A4A4A4A 一律视为 DIAL-TONE ,在链路初始化后的 DIAL-TONE 一律视为普通数据。
SATA 的底层是串行信号,涉及到如何在串行的 bit 流中界定 byte 边界的问题,为此,SATA 使用一种特殊的 ALIGN 原语来界定 byte 边界。ALIGN 原语是唯一一种最特殊的原语,它的首 byte 是 K28.5 ,而其它原语的首 byte 都是 K28.3 (关于 K28.3 和 K28.5 的概念,详见下文:8b10b编码),在 8b10b 编码下,K28.5 原语会产生一种独一无二的 10bit 组合模式,物理层负责识别这种模式,每当遇到这种模式,接收方就知道当前处于一个 10bit 的边界。
考虑到时钟频率具有一定的精度,在遇到 ALIGN 后的一段时间内,接收方仍能正确地界定 10bit 的边界,但是时间足够长后,还是会丢失边界,因此 SATA 要求双方都周期性地发送 ALIGN 原语,称为 ALIGN 插入机制:
注意:不能因为要插入 ALIGN 原语,就替换掉当前想要发送的 FIS 数据、 SOF 原语、EOF 原语。举例如下(其中 "DATA" 是 FIS 数据 dword )
我们在要发送 EOF 时刚好需要插入 2 个连续的 ALIGN 原语,不能把 EOF 替代掉,只能是推迟发送 EOF ,否则接收方将无法界定 FIS 的结尾。
8b10b 编码是指发送端把 1byte (8bit) 数据编码成 10bit 的编码(称为DC平衡码)来发送;8b10b 解码是指接收端把收到的 10bit 解码成原始的 1byte 。10bit 的平衡码的逻辑0和逻辑1的数量是大致平衡的,只存在3种情况:
之所以要传输DC平衡码,是为了能让接收端物理层的锁相环 (PLL) 从数据中恢复出时钟,而不至于失锁。
实际上, 8b10b 编码除了携带 1byte 外,还能携带 1bit 的额外的控制比特,它指示该 byte 是 K 还是 D 。SATA 用是否为 K 来区分是不是原语:即原语的第一个 byte 是 K-byte ,其余 byte 为 D-byte 。 而数据(非原语)的所有 byte 都为 D-byte 。
在 8b10b 编码的语境下,习惯上把 1byte (8bit) 的原始数据写为 Kxx.y 或 Dxx.y 的形式,其中 xx 是该byte的低5bit的十进制形式,y 是该byte的高3bit的十进制表示。之所以把低5bit和高3bit分开,是因为它们在后续是分别编码的。举例如图7。
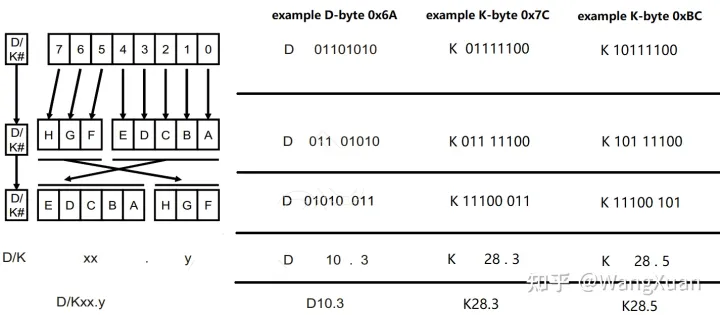
图7:8b10b编码下1byte原始数据的习惯表示
SATA 所使用的 D-byte 可以是任意的,但只用到了两种 K-byte ,即 K28.5 和 K28.3 。其中 K28.5 是 ALIGN 原语的首byte , K28.3 是其余原语的首byte 。
本文只提供 8b10b 编码的概览,不讲解编码算法的后续细节,如有兴趣详见参考资料[1]的 Appendix A : 8b/10b Encoding Tutorial 。
除了 ALIGN 和 CONT 原语外,其它原语都是为了控制 FIS 收发过程,因此我们要先了解 FIS 数据包的结构。
表2是 FIS 数据包结构,其中 FIS-type 字段和 CRC 字段固定是 1 dword。而 Payload 字段是数据字段,长度不定,可以是 0~2048 dword 。其中 CRC 不需要命令层发送或处理,因为传输层会自动在 TX FIS 中插入 CRC ;检查并删除 RX FIS 的CRC,并命令层报告 CRC 是否出错。
表2:FIS 数据包结构
| 字段 | FIS-type | Payload | CRC |
|---|---|---|---|
| 长度 (byte) | 4 | 0~8192 | 4 |
| 长度 (dword) | 1 | 0~2048 | 1 |
| 发送行为 | 需要命令层发送 | 需要命令层发送 | 不需要命令层发送。传输层插入 |
| 接收行为 | 命令层可见 | 命令层可见 | 命令层不可见。传输层检查、删除并报告CRC错误 |
在下文的语境中,我们用名词?FIS长度?指代 FIS-type + Payload 字段的总长度(最小 1 dword, 最大 2049 dword),而不包括 CRC 。
FIS 以 dword 为单位(长度能整除4 byte)习惯上用 dword 来表示 FIS 。例如一个 FIS长度=5 的 FIS 如下:
其中第一个 dword 00258027 是 FIS-type ,后续的 4 个 dword 是 payload 。
注意 FIS 数据的也是小端序,例如对于第一个 dword E0023456 ,在底层最先传输的byte是 56 ,最后传输的byte 是 E0 。
FIS-type 字段和 Payload 字段的所有 dword 会依次参与 CRC 的计算。计算方法用 Verilog 语言风格的伪代码表示如下:
在接收方,用同样的算法算出 CRC ,并与发送方发送的 CRC 进行对比,匹配则无错误,不匹配则有错误,该错误需要报告给命令层。
除了 ALIGN 和 CONT 原语外,表1中的其它原语几乎都用来控制 FIS 收发过程。这里举一个例子如下(注意这里省略了周期性插入 ALIGN 原语,也省略了下文要讲的重复原语加扰机制),其中 "DATA" 代表一个 FIS 数据 dword 。
对以上过程解读如下:
从该过程我们可以看到,当一个通道发送 FIS 时,另一个通道在发送 R_RDY, R_IP, R_OK, R_ERR 这四种原语来控制对方发送 FIS 的过程,因此在一个时间点上 FIS 不可能双向发送。换句话说,SATA在物理上是全双工,在逻辑上是半双工。
另外,由于 HBA 和 device 都有发起 FIS 发送过程的权力,因此有可能刚好 HBA 和 device 都在发送 X_RDY,同时试图启动 FIS 发送。SATA规定这种情况下 HBA 总是要让着 device : HBA 只要检测到了 device 发来的 X_RDY ,就要放弃当前的发送进程,转而发送 R_RDY ,准备接收 device 发来的 FIS 。
加扰的目的是让 SATA 电缆上传输的0-1序列更加杂乱,从而让电磁辐射更加接近白噪声(而不是集中分布于某个频率),从而减少电磁干扰(EMI)。
FIS加扰器会生成一个伪随机数序列,每次产生一个 dword ,把它与 FIS 数据的 dword 求按位异或,就得到加扰后的 FIS 。FIS 的 FIS-type字段、Payload字段、CRC字段都要进行加扰。而任何原语都不进行 FIS 加扰。
FIS 加扰的过程用 Verilog 语言风格的伪代码表示如下:
在接收端需要对 FIS 进行解扰,解扰是加扰的对称操作,只需要用同样的算法生成伪随机的 dword 序列,对收到的 FIS 进行按位异或运算。因为两次异或后数据不变,因此解扰后能恢复出加扰前的数据。
注意发送端和接收端都要在 FIS 未在传输时对加扰器/解扰器进行复位,也就是把以上伪代码中的 scram 寄存器复位为 0xFFFF 。复位后,生成的伪随机 dword 序列是固定的,这里列出前 6 个 dword 如下:
本节会讲到 CONT 原语的作用。
上一节的 FIS 加扰机制仅仅解决了 FIS 传输时的 EMI 问题,但是 SATA 有很多时候不在发送 FIS ,而是在发送重复的原语(比如空闲时重复发送 SYNC 原语),这种重复的模式也会引起电磁辐射的频谱集中于某个频段,导致 EMI 问题。因此 SATA 对重复原语的引入了 CONT 原语和加扰机制。
在重复加扰机制中 ,SATA 把原语分为4类:
对于可重复原语,如果连续重复出现三次以上,SATA 要求把第3个重复的原语替换为 CONT ,然后从第4个重复原语开始替换为垃圾数据,这个垃圾数据是一个伪随机 dword 序列,其生成算法与上一节讲的 FIS 加扰用的伪随机数生成算法一样。不过两个伪随机数生成器不能互相影响,应该独立工作。另外,垃圾数据会被接收端直接区分出来并丢弃,所以接收端不在乎垃圾数据的值,SATA也并不要求发送端对垃圾数据的伪随机数生成器进行复位,它可以永远不复位。
举个例子如下(其中 "DATA" 代表一个FIS数据 dword,"GARB" 代表一个垃圾数据 dword):
现在我们就能理解:链路初始化后,SATA上实际传输的每个 dword 只可能分为三种:原语、FIS数据、或者 CONT 原语后的垃圾数据。
有两个特殊的可重复原语:HOLD 和 HOLDA ,它们在重复最后一次时必须保留,不能被替换为 CONT 或垃圾数据。这是因为 HOLD 和 HOLDA 会被插入在 FIS 数据中(下文的流控一节中会讲到),在重复加扰时,为了让接收端能把垃圾数据和FIS数据区分开,要求在 HOLD 和 HOLDA 重复的最后一次时,不用 CONT 或 垃圾数据替换它,而是传送 HOLD 和 HOLDA 本身。
HOLD 和 HOLDA 的重复加扰举例如下。其中错误的重复加扰出现了 "GRAB" 和 "DATA" 连续的情况,因为接收方无法从数据本身来区分一个数据是FIS数据还是垃圾数据,因此这样会引起混淆错误。而正确的加扰用 HOLD 和 HOLDA 原语本身把FIS数据和垃圾数据分开了,不存在混淆问题。
另外,ALIGN 对重复加扰机制来说是一种特殊的原语,重复加扰机制不会被 ALIGN 的插入机制所打断。举例如下,重复加扰前的这个序列被周期性地插入了 ALIGN 。可以看出,重复加扰机制直接无视了 ALIGN 原语,在 ALIGN 前后出现的重复原语仍被视为重复的。
最后需要提一下,原语的重复加扰的机制实际上比较宽松,发送方可以宽松地进行重复加扰,从而简化一些逻辑:
但是,接收端必须能正确处理满足规范的所有情况。
重复加扰机制总结为以下原则:
本节会讲到 HOLD 和 HOLDA 原语的作用。
因为硬盘介质的读写速率与 SATA 接口的速率往往并不匹配,因此传输层规定了流控(Flow Control)机制,流控依赖于 HOLD 和 HOLDA 原语,包括两种流控:发送方流控和接收方流控。
发送方流控:当发送方暂未准备好待发送的 FIS 数据时(例如读硬盘的速率慢于SATA接口速率),发送方可以插入 HOLD 原语来填空,这样就能支持“断断续续”地发送数据。发送方流控的逻辑如下:
举例如下:
接收方流控:当接收方暂不能接收 FIS 数据时(例如写硬盘的速率慢于SATA接口速率),接收方可以向发送方发送 HOLD 原语,告诉发送方“不要发的这么快,我接受不了了”,发送方就会暂停发送数据并向接收方发送 HOLDA 原语来填空。
注意:因为从接收方发送 HOLD 到发送方插入 HOLDA 之间有一个来回的时间差,因此接收方需要一个接收缓存,在缓存接近满(而不是完全满)的时候发送 HOLD ,直到收到发送方发来的 HOLDA 时,缓存仍然能存下这个时间差内传来的数据,而不会导致溢出。SATA Spec 规定缓存接近满是指缓存仅剩下 20 dword (80 byte) 的空间,因此也规定这个时间差不能大于 20 个 dword 的传输时间。
接收方流控的逻辑如下:
举例如下:
我们已经看到,链路层和传输层的机制众多且复杂,但是它的目的并不复杂,就是考虑如何用两对对高速串行的差分线来实现可靠的 FIS 数据包传输,要能保证时钟恢复、字节对齐、减少EMI、检查误码、在速率不匹配时提供流控机制。建议读者回顾图5来理解各个机制间的关系。
上文讲解的所有内容都在链路层和传输层。本节简单地讲解命令层中的 DMA 读写命令,展示如何用 FIS 包实现硬盘读写。
前文讲过,FIS 的第一个 dword 是 FIS-type 字段,它决定了FIS类型,如表3。
表3:FIS 类型
| FIS-type 字段 (16进制, X代表dont care) | FIS 类型 | FIS长度 (FIS-type+Payload) (dword) |
|---|---|---|
| XXXXXX27 | HBA to device register | 5 |
| XXXXXX34 | device to HBA register | 5 |
| XXXXXXA1 | set device bits | 2 |
| XXXXXX5F | PIO setup | 5 |
| XXXXXX39 | DMA activate | 2 |
| XXXXXX41 | First Party DMA Setup | 7 |
| XXXXXX46 | data | 1~2049 |
| XXXXXX58 | BIST activate | 3 |
要进行简单的 DMA 读写,实际上只需要 XXXXXX27 、XXXXXX34 、XXXXXX39 、XXXXXX46 这四种类型的 FIS 。
在链接初始化后、读写前,HBA 要向 device 发起 identify 请求 FIS ,该 FIS 是 HBA-to-device Register 类型的,包含 5 个 dword :
device 会响应两个 FIS :
然后就可以发起读写请求,DMA 读写以扇区(sector)为单位,每个扇区 512 byte (128 dword) ,一次可以指定读写连续扇区的数量。用 48-bit LBA (logic block address, 逻辑块地址) 对扇区进行寻址,例如 LBA=0x000001234567 就代表第 0x1234567 个扇区。
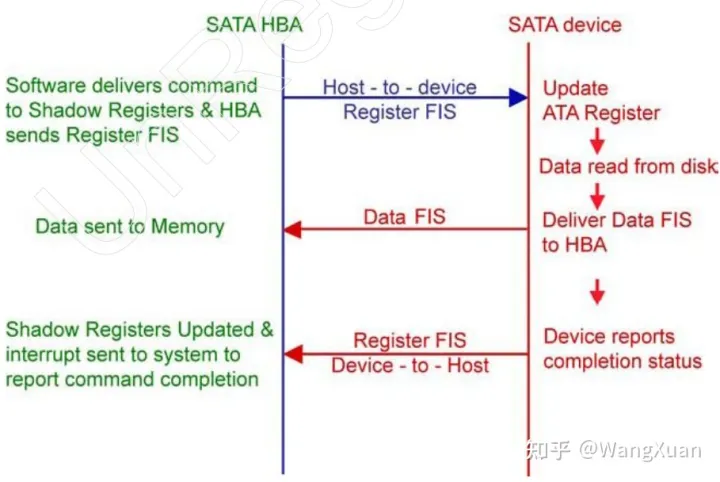
图8:DMA读时序图
DMA 读扇区的时序图如图8。首先 HBA 要发送一个 5 dword 的 HBA-to-device Register 类型的读请求 FIS ,格式如下。其中 XXXXXX 是 LBA[23:0] ,YYYYYY 是 LBA[47:24] 。ZZ 是读写的扇区数量,一次可以读一个或多个扇区。
例如我们要对 LBA=0x0000A1234567(也就是第 0xA1234567 个扇区)进行读,连续读 4 个扇区,则 HBA 应该发送命令 FIS :
然后硬盘会发送读出的数据(data 类型的FIS)。考虑到FIS的Payload字段最大为 2048 dword,如果HBA请求写的扇区数量≤16(≤2048 dword) ,硬盘只会响应1个FIS。否则就会响应多个FIS。格式为:
在所有数据发送完后,device 还会发送给 HBA 一个 device-to-HBA Register 类型的 ,长度为 5 dword 的 FIS 来显示自身状态。
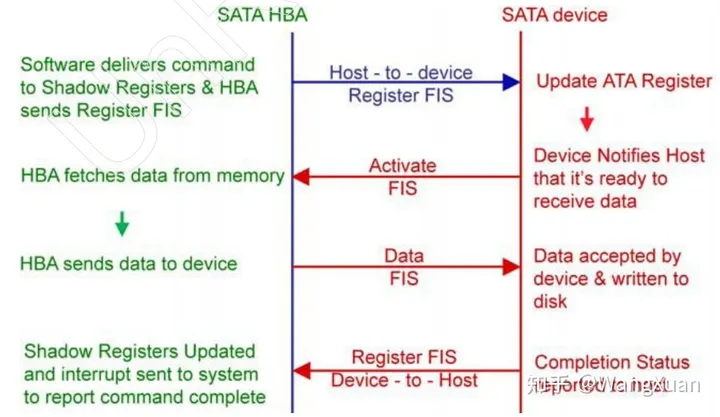
图9:DMA写时序图
DMA 写扇区的时序图如图9。首先 HBA 要发送一个 5 dword 的 HBA-to-device Register 类型的读请求 FIS ,格式如下。其中 XXXXXX 是 LBA[23:0] ,YYYYYY 是 LBA[47:24] 。ZZ 是读写的扇区数量,一次可以写一个或多个扇区。
例如我们要对 LBA=0x000000000001 进行写,只写 1 个扇区,则 HBA 应该发送命令 FIS :
然后硬盘会响应一个 DMA activate 类型的 FIS ,该 FIS 只有1 dword (Payload长度=0) ,格式如下,告诉HBA现在可以发送写数据了。
随后 HBA 要发送读出的数据(data 类型的FIS)。考虑到FIS的Payload字段最大为 2048 dword,如果HBA请求写的扇区数量≤16(≤2048 dword) ,HBA就要发送1个FIS。否则就要发送多个FIS。格式为:
在所有数据发送完后,device 还会发送给 HBA 一个 device-to-HBA Register 类型的 ,长度为 5 dword 的 FIS 来显示自身状态。
至此我们简单了解了读写硬盘的方法,要了解更多的命令层协议请阅读参考资料 [1]。
[1] SATA Storage Technology :?https://www.mindshare.com/Books/Titles/SATA_Storage_Technology
[2] Serial ATA: High Speed Serialized AT Attachment :?https://www.seagate.com/support/disc/manuals/sata/sata_im.pdf
[3] Nikola Zlatanov : design of an open-source sata core :?https://www.researchgate.net/publication/295010956_Design_of_an_Open-Source_SATA_Core
[4] Louis Woods et al. : Groundhog - A Serial ATA Host Bus Adapter (HBA) for FPGAs :?https://ieeexplore.ieee.org/abstract/document/6239818/
[5] 开源 SATA Gen2 host (HBA) :?https://github.com/WangXuan95/FPGA-SATA-HBA



