
5月和朋友聊天,决定开设一个公众号,以博客的方式每天记载Python知识和有趣的内容。之后经过前期准备与摸索终于在5月31号,首次在公众号尝试发文,而今已过两月时间。
不知道什么时候开始,中国出现了南抖音、北快手的互文格局(东市买骏马,西市买鞍鞯...)。刚才提到了,之前比较喜欢刷抖音,对于我这种佛系程序猿,看网上这些整容妹子基本一个样。喜欢抖音主要是两个初衷,学做菜听音乐。朋友之前常说,人家抖音看妹子看的乐呵呵,你看人家做菜也能津津有味,一个人在那儿傻笑...民以食为天,我看到色香味俱全的菜,做的那么好吃的乐呵乐呵还不行么。
抖音捧红了很多人,也让很多本不怎么让大家熟知的歌曲、BGM,经过翻唱、混剪与视频搭配,从而传播大街小巷。什么“若不是你,突然闯进我心里...”亦或者“也许未来遥远在光年之外,我愿守候未知里为你等待...”,成了大家闲时在嘴边哼唱的调调。那么,有没有想过将这些好听的剪辑批量下载下来呢?
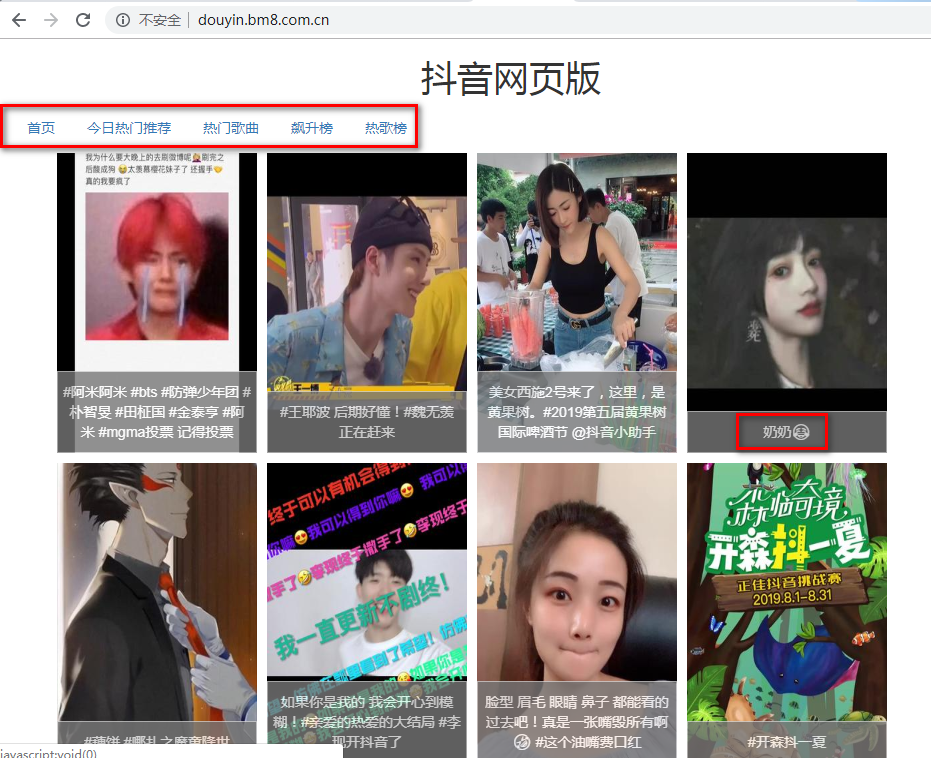
python下载抖音内容的帖子网上有一些,但都比较麻烦,需要通过adb连接安卓手机后,模拟操作。我这么懒,这种事儿玩不来...那么,该如何获取抖音内容呢?网上搜了下大概有两种方式,一个是浏览器插件快抖,另外一个是我今天要说的抖音网页版。其实这两者差别不是很大,都是先将抖音内容下载至服务器后,通过开发简单网站配置域名后,让大家访问。让我们来看看抖音网页版:
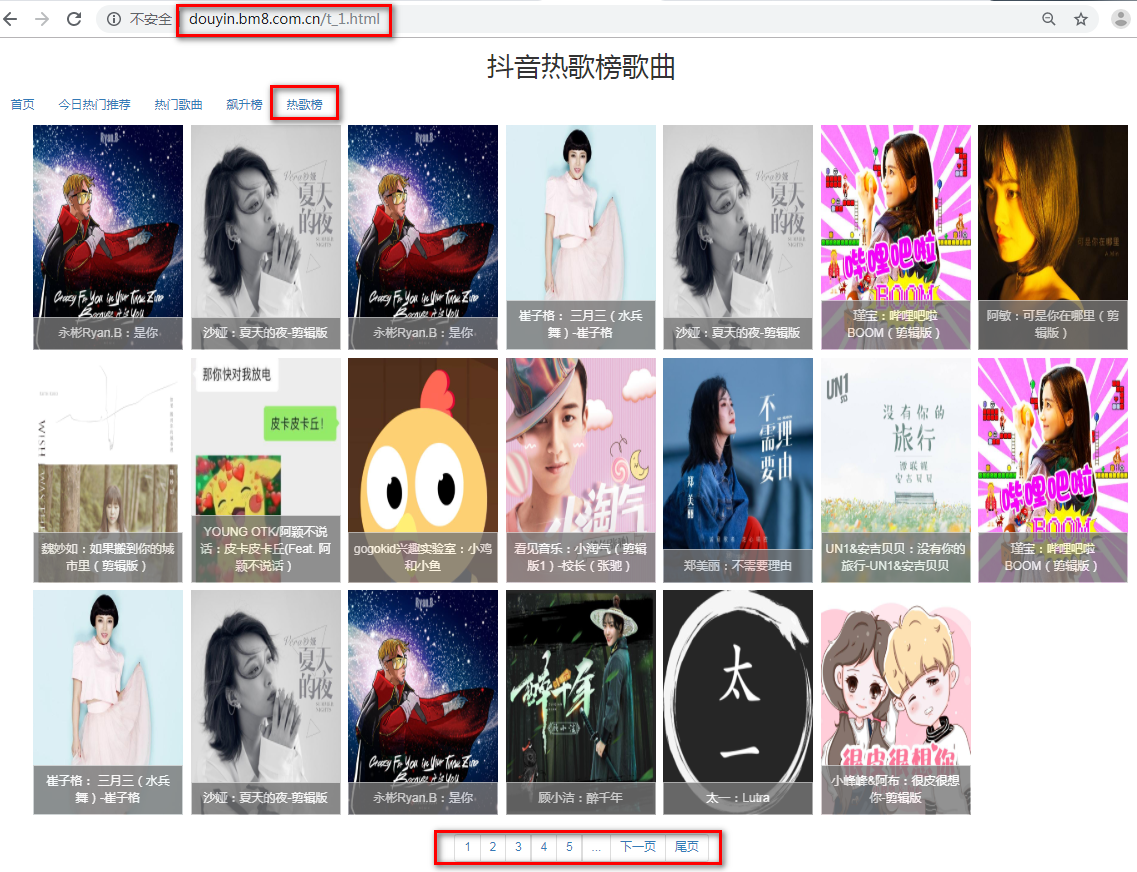
大家先开看看这个抖音热歌榜歌曲,每页20首歌曲,一个55页。但细不细心大家都能发现,很多歌曲存在重复的问题。所以,等下爬虫的时候,我们需要先准备一个music_list,用来识别这首歌曲是否已经下载过了...

网页比较简单,一个div中包裹了一个ul>li*20,我们是不是该这样获取:
如果你说是,那么一定没有好好看我前天整理的文章通过哪吒豆瓣影评,带你分析python爬虫快速入门:https://www.jianshu.com/p/ae38f7607902,我在文章中专门提到了一个小技巧,通过使用attr的属性进行快速解析,那么最快速的获取方式是:
我们只需要获取所有的a标签,切这些标签中包含onclick这个属性即可。
我们解析到的内容通过attr['onclick'],可以得到他的属性open1('夜','http://p9-dy.byteimg.com/obj/61a20007a98954b0831d',''),如何能快速获取歌曲名字和url呢?这里我们需要用到一个eval的小技巧:
ps:今天一个朋友说我写代码没注释,我这是现身说法的告诉你,如何能写出让别人压根看不懂的代码,就是不写注释啊,哈哈!
其实,代码我都在文章中一点一点的讲解了,所以没有写,但秉承着害怕大佬们取关的心态,我还是把注释加上吧...
总体来说实现比较简单,全部代码如下:
来让我们看看效果吧:
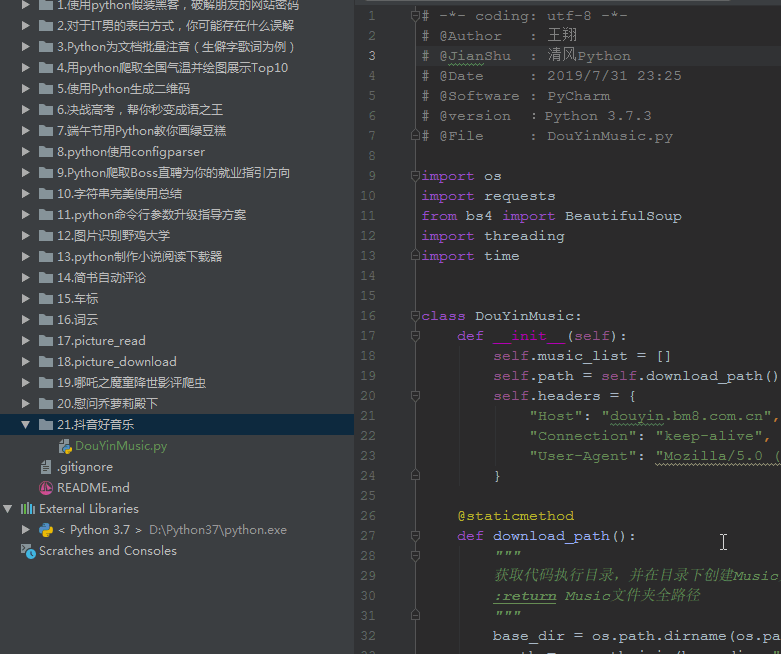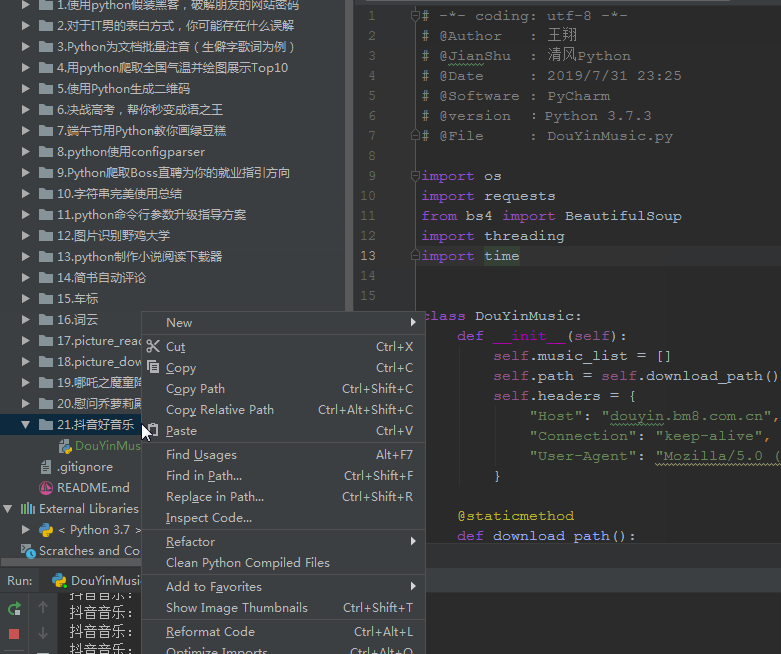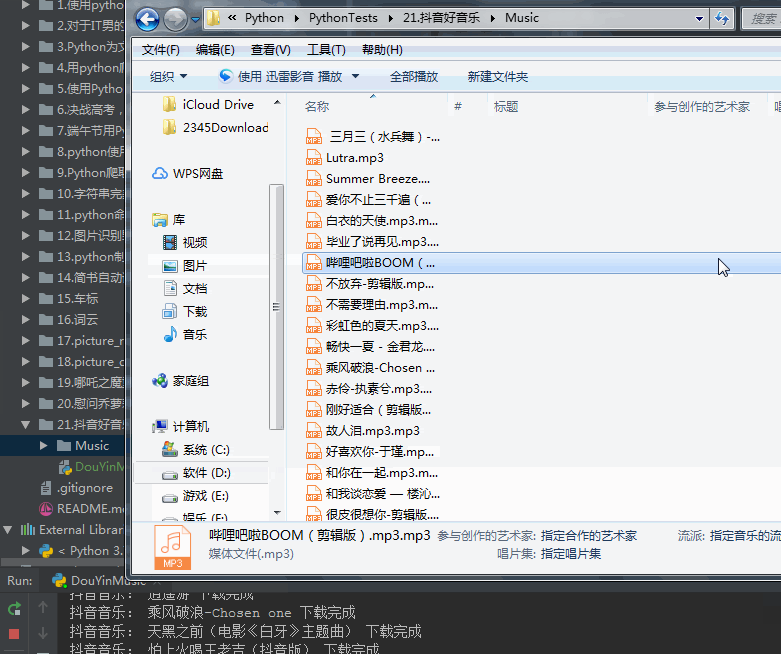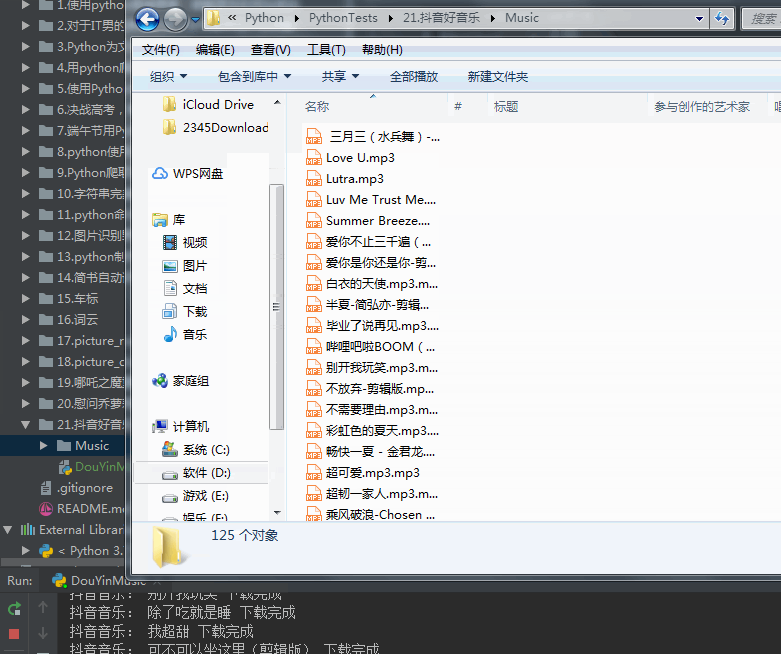
网站是通过nginx负载均衡搭建的,有一些链接已经失效了。最终下载了不重复的592首抖音音乐。

OK,今天的内容就到这里,如果觉得内容对你有所帮助,欢迎点击文章右下角的“在看”。
代码与下载好的音乐,如果大家喜欢,公众号回复即可获取百度云下载链接。
期待你关注我的公众号,如果觉得不错,希望能动动手指转发给你身边的朋友们。
希望每周一至五清晨的7点10分,都能让清风Python的知识文章叫醒大家!谢谢……
上一篇:华为智能光伏太阳能优化器MERC-1300W-P华为太阳能电池板优化器1300W
下一篇:抖音适合投放招聘类APP广告吗?效果如何?



